Machine Learning에서 어떤 모델이 더 좋은 모델인지 어떻게 판단할까?
결론부터 말하자면 Accuracy와 F1-Score를 이용할 수 있다!
그리고 그 F1-Score를 이해하기 위해 Precision과 Recall(=Sensitivity)에 대한 이해가 필요함
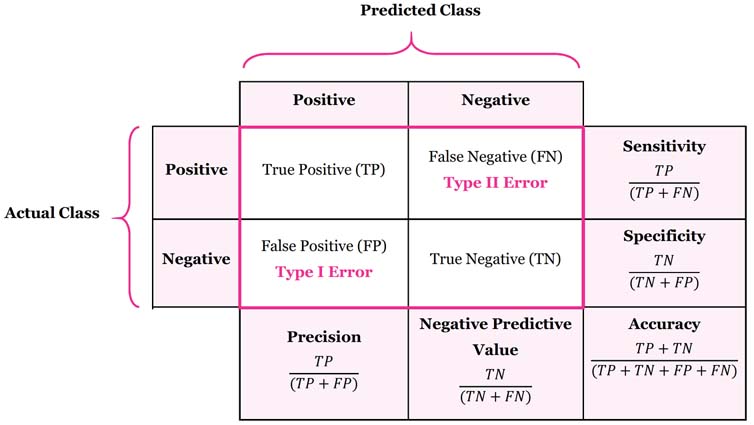
혼동행렬
혼동행렬(Confusion Matrix) :
어떤 개인, 모델, 검사도구, 알고리즘의 진단·분류·판별·예측 능력을 평가하기 위하여 고안된 표

Predicted : 예측
Actual : 실제
예측한 값과 실제 값이 있을 때
아래 4가지의 조합
True : 예측 = 실제
False : 예측 ≠ 실제
Positive : 긍정 클래스를 예측
Negative : 부정 클래스를 예측
True Positive : 예측 = 실제 & 긍정 클래스를 예측
True Negative : 예측 = 실제 & 부정 클래스를 예측
Flase Positive : 예측 ≠ 실제 & 긍정 클래스를 예측
False Negative : 예측 ≠ 실제 & 부정 클래스를 예측
여기서 말하는 '긍정'과 '부정'은 질문에 대한 대답이 'O'인지 'X'인지에 대한 것 뿐이며
일반적으로 얘기하는 긍정적이거나 부정적인 의미가 아니다!
예를 들어, 어떤 사람이 코로나 감염이 의심되어 검사를 했을 때, 검사 결과는 양성(Positive) 또는 음성(Negative)일 것
'양성' 이라고 예측했는데 실제로 '양성' 인 경우 → TP
'음성' 이라고 예측했는데 실제로 '음성' 인 경우 → TN
'양성' 이라고 예측했는데 실제로 '음성' 인 경우 → FP
'음성' 이라고 예측했는데 실제로 '양성' 인 경우 → FN
이 검사 도구를 평가하는 입장에서도 이를 평가 기준으로 삼을 수 있다
이 예시에서 문제가 되는 상황은 FP와 FN의 상황인데
감염병의 확산을 막고자하는 정부의 입장에서 생각해본다면
차라리 FN의 상황보다 FP의 상황이 나을 것이다
예측은 양성이지만, 실제로 음성인 경우(FP)는 개개인이 억울하게 격리를 해야하는 상황이겠지만
예측이 음성이지만, 실제로 양성인 경우(FN)는 감염병을 확산시킬 수도 있는 문제가 발생하기 때문에
이 검사 도구를 평가하는 입장이나 정부의 입장에서는 FN의 경우를 최대한 줄이려고 노력할 것이다
이처럼 처한 상황에 따라서
Precision을 중요하게 생각해야 될 때도 있고 Recall(Sensitivity)를 중요하게 생각해야 할 수도 있다
정확도
정확도(Accuracy) : 예측이 현실에 부합할 확률; ACC
$$ \frac{(TP+TN)}{(TP+TN+FP+FN)} $$
- 정확도↑ → 예측이 제대로 적중한 경우↑
- 데이터가 균형적(balanced data)일 때 효과적인 지표
- 데이터가 균형적이지 않다면 잘못된 판단을 하게 될 수 있음 (참조에 허민석님의 영상 참조)
정밀도 (P)
정밀도(Precision) : 긍정 클래스로예측한 것들 중 실제 긍정 클래스의 비율;
PPV(Positive Precision Value)
$$ \frac{(TP)}{(TP+FP)} $$
- 정밀도↑ → 안정성↑, 분산(variance)↓
- 부정 클래스 예측에 대한 정보 제공 불가
- 재현율과 상충관계(trade-off)
재현율 = 민감도 (R)
재현율(Recall) 또는 민감도(Sensitivity) :실제긍정 클래스들 중 긍정 클래스로 예측한 것들의 비율;
TPR(True Positive Rate)
$$ \frac{(TP)}{(TP+FN)} $$
- 실제 부정 클래스에 대한 정보 제공 불가
- 정밀도와 상충관계(trade-off)
예를 들어, 이미지에서 사람을 찾아주는 영상인식기술 A와 B가 있다고 생각해보자
- A는 이미지에서 사람을 99.99% 인식(FN↓)하지만 이미지 1장 당 평균 10건 정도의 오검출(FP↑)이 발생한다
(사람이 아닌 부분도 사람이라고 검출하는 경우가 많다는 의미)
- B는 이미지에서 사람을 50% 밖에 인식하지 못하지만 오검출은 거의 발생하지 않는다
(많은 사람을 인식하지는 못해도 정확하게 사람을 인식한다는 의미)
그렇다면 어떤 기술이 더 뛰어난 기술인가? → 'A가 검출율이 99.99%이기 때문에 더 뛰어난 모델이다' 라고 할 수 없다
대신, A는 상대적으로 Recall(=Sensitivity)이 높은 모델이고, B는 상대적으로 Precision이 높은 모델이라고 할 수 있다!
왜?
- A의 경우, 사람을 99.99% 인식한다는 것은 상대적으로 FN이 낮다고 볼 수 있고, (→ 높은 Sensitivity)
이미지 1장 당 평균 10건 정도의 오검출이 발생한다는 것은 상대적으로 FP가 높다고 볼 수 있다. (→ 낮은 Precision)
- B의 경우, 사람을 50% 인식한다는 것은 상대적으로 FN이 높다고 볼 수 있고, (→ 낮은 Sensitivity)
오검출이 거의 발생하지 않는다는 것은 상대적으로 FP가 낮다고 볼 수 있다. (→ 높은 Precision)
F1 Score
F1 Score : 정밀도(P)와 재현율(R)의 조화 평균
$$ \frac{2PR}{P+R} $$
- 데이터가 불균형적(imbalanced data)일 때 효과적인 지표
그렇기 때문에,
데이터가 balanced data인지 imbalanced data인지 고려하여
Accuracy와 F1 Score를 모두 고려한다면
더 나은 판단을 할 수 있을 것!
참고
친절한 AI - 분류 모델 지표의 의미와 계산법 : True Positive, False Posivite, True Negative, False Negative
허민석 - [머신러닝] 다중 분류 모델 성능 측정 (accuracy, f1 score, precision, recall on multiclass classification)

'Math & Statistics' 카테고리의 다른 글
| Markov Chains, 마르코프 체인 (0) | 2022.05.21 |
|---|---|
| Taylor series, 테일러 급수 (0) | 2022.05.13 |
| 확률과 통계 개념정리 (0) | 2022.03.12 |
| Likelihood, MLE, Cross Entropy (0) | 2022.03.11 |
| Essence of linear algebra 선형대수학 (0) | 2021.12.02 |